一.简介
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。网址:https://jsoup.org/
二.代码实现
1.maven里引用jsoup
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.2</version>
</dependency>
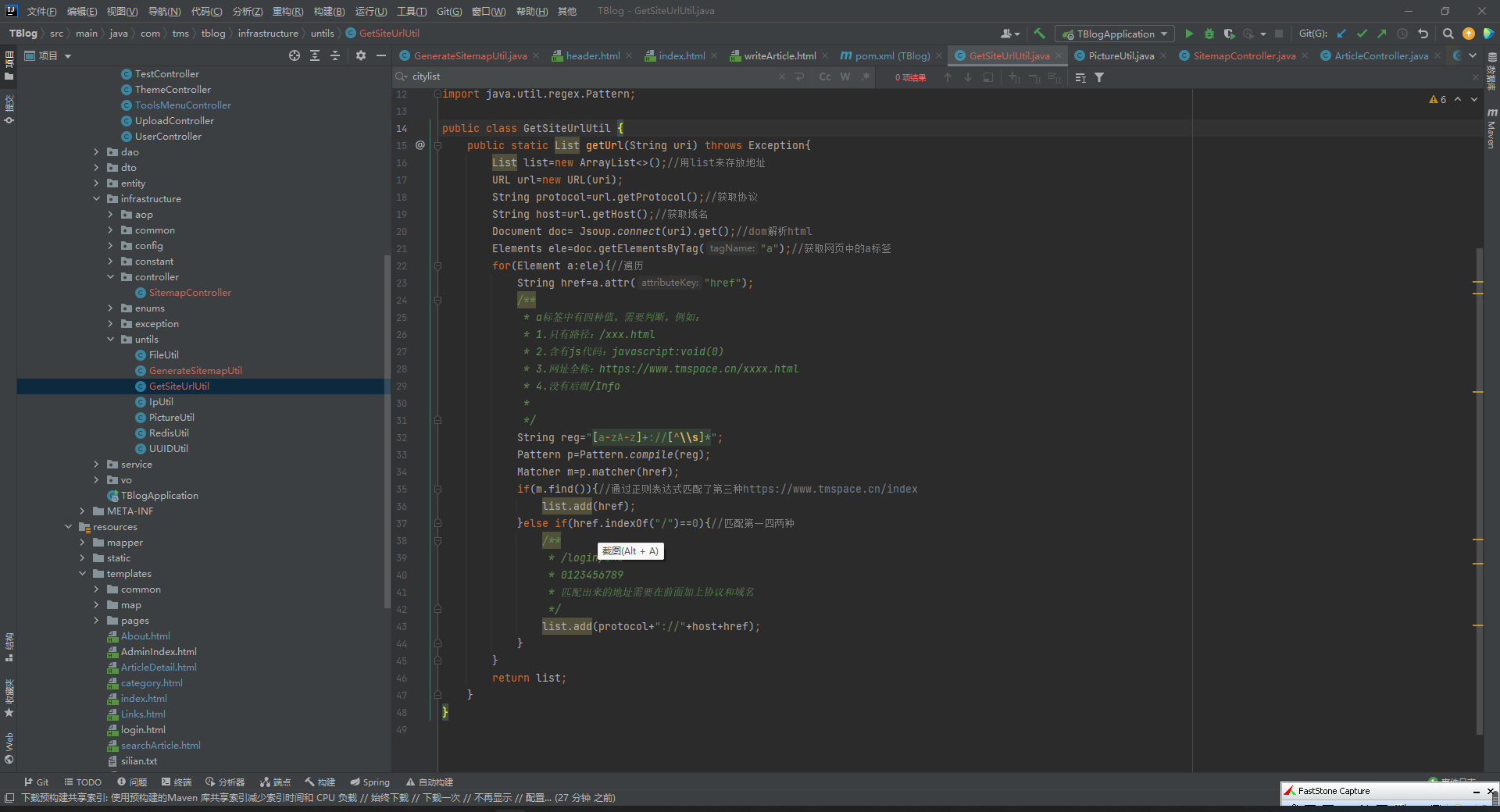
2.编写一个工具类
package com.tms.tblog.infrastructure.untils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetSiteUrlUtil {
public static List getUrl(String uri) throws Exception{
List list=new ArrayList<>();//用list来存放地址
URL url=new URL(uri);
String protocol=url.getProtocol();//获取协议
String host=url.getHost();//获取域名
Document doc= Jsoup.connect(uri).get();//dom解析html
Elements ele=doc.getElementsByTag("a");//获取网页中的a标签
for(Element a:ele){//遍历
String href=a.attr("href");
/**
* a标签中有四种值,需要判断,例如:
* 1.只有路径:/xxx.html
* 2.含有js代码:javascript:void(0)
* 3.网址全称:https://tmspace.cn/xxxx.html
* 4.没有后缀/Info
*
*/
String reg="[a-zA-z]+://[^\\s]*";
Pattern p=Pattern.compile(reg);
Matcher m=p.matcher(href);
if(m.find()){//通过正则表达式匹配了第三种https://tmspace.cn/index
list.add(href);
}else if(href.indexOf("/")==0){//匹配第一四两种
/**
* /login/ind
* 0123456789
* 匹配出来的地址需要在前面加上协议和域名
*/
list.add(protocol+"://"+host+href);
}
}
return list;
}
}
3.编写一个调用的controller
package com.tms.tblog.infrastructure.controller;
import com.tms.tblog.dto.ResultDto;
import com.tms.tblog.infrastructure.untils.GenerateSitemapUtil;
import com.tms.tblog.infrastructure.untils.GetSiteUrlUtil;
import io.swagger.annotations.Api;
import lombok.extern.log4j.Log4j2;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.servlet.http.HttpServletRequest;
import java.util.List;
/**
* 生成网站地图Controller
*/
@Api(tags = "生成网站地图Controller")
@RestController
@Log4j2
@RequestMapping("/tblog/Sitemap")
public class SitemapController {
@RequestMapping("/getUrl")
public ResultDto getUrl(HttpServletRequest req) throws Exception {
ResultDto res = new ResultDto();
String Url = "https://tmspace.cn";
List list = GetSiteUrlUtil.getUrl(Url);
res.setData(list);
return res;
}
}
三.最后实现效果

评论 (0)
暂无评论,快来抢沙发吧